
A post by Kevin Lande
Images occupy a peculiar position in our understanding of representation—the capacity of one thing to be about another. On the one hand, the image is the paragon of representation. An image of a hand re-presents its subject matter, whereas the linguistic phrase “right hand” bears a more abstract, arbitrary relation to what it signifies. Images can teem with seemingly inexhaustible significance—depicting, for example, not just a hand, but a certain number of figures in a certain arrangement—while symbols of language tend to have a lean, almost brutal semantic economy.

On the other hand, images are commonly also taken to be rudimentary and lacking for any definite structure or meaning. Language, by contrast, is the “infinite gift” (Yang, 2006), allowing for unbounded creativity in thought and communication. That gift is fueled by a lexicon of basic words or symbols. The lexicon feeds a grammatical engine, comprising rules for how those words can be combined to generate novel meaningful phrases. Looking beyond language, Roland Barthes (1977) asked: “can analogical representation (the ‘copy’) produce true systems of signs and not merely simple agglutinations of symbols?” Barthes observed that the image, in contrast to language, “is felt to be weak.” “Pictures… have no grammatical rules,” writes Flint Schier (1986). Even the book Visual Grammar (Leborg, 2006) begins by noting that “Visual language has no formal syntax or semantics.” The grammar of a language explains its expressive power. The object of Leborg’s “grammar” is not to explain, but to describe, to classify, and to recommend (see also Hopkins, 2023). Language has an engine; images have only a dashboard.

Kevin Lande is an Assistant Professor of Philosophy at York University, in Toronto. He works in philosophy of mind, perception, and cognitive science, focusing on understanding how minds construct representations, or models, of the world and what form those representations take.
But the view that images lack a grammar lacks imagination—as does the related view that having a grammar is something unique to a language. Our comprehension of images might well be explained by our possessing a grammar, or an image engine: a systematic ability to comprehend a set of images by understanding how they are organized from more basic image elements (Clowes, 1971; Ullman et al., 2017). Understanding this image engine may be crucial not just to understanding how we view images and use them in visual communication but also how we (and, someday, artificial systems) can perceive and think with images.
Uneven Landscapes
The landscape of possible phrases and sentences is not uniform. Grammatical rules carve out the valleys where phrasal structures flow and the hilltops where no grammatical, “well-formed” expression can live. In the landscape of my idiolect, “Hidden in his coat is a red right hand” lives in the valley of the well-formed; “Hand coat his in right” is at the ill-formed peak.
What about the landscape of possible images? John Haugeland writes that in images, “every … shape is allowed—nothing is ill-formed” (1981, p. 22). But the space of possible images is not so uniform. Or, rather, we do not treat all possible images uniformly.
Here are four natural images (under “natural image” I include photographs and realist drawings or paintings of ordinary scenes you might encounter while walking around):

Now let’s combine them into one:

I have great difficulty treating this combination as a natural image in its own right. Instead, I grasp it as a different kind of image altogether: a collage or a “quadriptych,” a juxtaposition of four separate images. In fact, the image is just a single photograph, by the artist Bela Borsodi, which has been cleverly composed to look like four separate images.
That fact that we treat this one image as a juxtaposition of four separate images suggests that the set of what we are prepared to treat as natural images is not “closed under arbitrary combination.” If you take arbitrary images, or image-parts, and piece them together, you are not guaranteed to get something that you will be prepared to treat as a unified image of the same sort. The combined image does not inhabit the same valley as the four sub-images.
This is explicable if the terrain of comprehensible images has been carved out by a combinatorial engine—a grammar. This grammar might have something like a rule of connecting lines: for two adjacent image patches to compose (something that we would treat as) a natural image, there must be lines in each of the image patches that could be connected by smooth curves. The juxtaposition of the four sub-images, though physically possible, violates a psychological rule of our image engine. So, so far as our image-comprehension abilities are concerned, the juxtaposition is not itself a natural image.[1]
At this point, we should distinguish between one’s core competence with images—one’s systematic abilities to make sense of what images depict (Gombrich, 1960; Sober, 1976; Schier, 1986; Willats, 1997)—and one’s background expectations, beliefs, and what one can “infer” from the image with sufficient thought (Abusch, 2020; Fan et al., 2019). Perhaps you simply don’t expect the image above to be a single image, though you can learn that it is (see Kulvicki, 2020, pp. 28-32). Perhaps one’s failure to grasp Borsodi’s composition as a unified image does not reflect a limitation of one’s pictorial competence so much as the rigidity of one’s expectations.
But another option is that even if you can come to learn that it is a single image and you can laboriously map out the scene that it depicts, this understanding ventures beyond your core competence with images. Perhaps your hard-won success in taking Borsodi’s photograph as a single image does not reflect your ability to grasp images so much as your ability to make inferences about the photo. The more basic failure to grasp the photo as a single natural image reflects the boundaries of the combinatorial engine with which you comprehend images. Overcoming those boundaries requires captions, conversations, or contemplation.
Each of these alternatives is an empirical hypothesis about what is going on inside the head of the image-viewer. I don’t mean to convince you that the latter story is the correct one, only that it is worth taking seriously.
Disambiguation
Consider Katsushika Hokusai’s print, below. The print obviously depicts some trees in the foreground, which are closer to the image plane and which partly occlude the border of Mount Fuji in the background. But the very same image could have been projected by a “Potemkin scene,” in which both mountain and tree are elements of a flat façade on the same depth plane, and in which there is no object continuing on behind the tree.
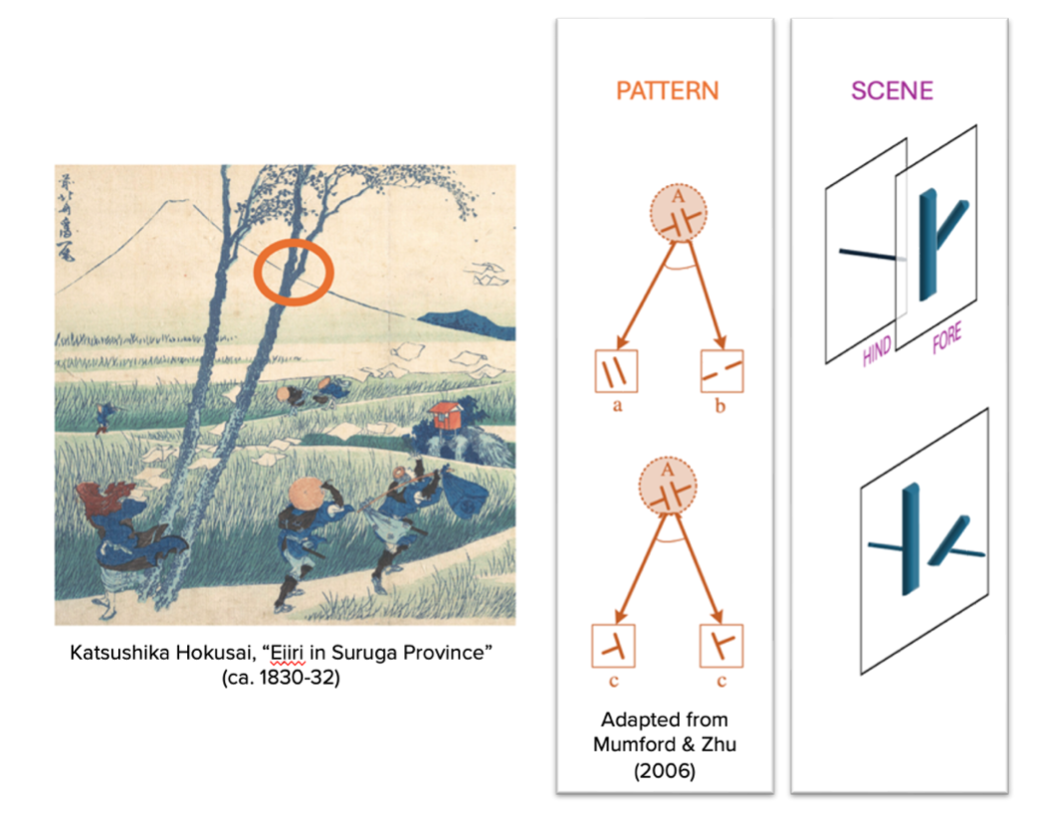
One can, as a result of captions, conversations, or contemplation, infer that the image depicts a Potemkin scene (Abell, 2009; Abusch, 2020; Kulvicki, 2020). But surely most of us default to taking the image as depicting “obvious features of pictorial content like depth and shape” (Greenberg, 2021, p. 859; Sober, 1976). Even if we are persuaded that the image is about a Potemkin scene, we tacitly understand that this is a non-standard interpretation, and we have great difficulty completely ignoring the standard interpretation (Perdreau & Cavanagh, 2011). The Potemkin interpretation is not something one naturally extracts from the image; it is something one gleans from outside context.
Perhaps our systematic and persistent tendency to see the image as depicting connected shapes at different depths stems from our image engine (Clowes, 1971). The engine treats the curved lines adjoining the mountain-shape as one “unit” in the image, while treating the lines bounding the tree-shape as a separate unit. We parse the image, treating it as a combination of elements that depicts “an occlusion configuration with two layers,” rather than as a different combination that depicts “a butting/alignment configuration at one layer” (Zhu and Mumford, 2006, p. 283).
José Luis Bermúdez writes that “pictorial representations do not have a canonical structure. Their structure can be analyzed in many different ways (corresponding to the jigsaw puzzles that one can construct from it)” (2010, p. 47). But different analyses make for substantively different interpretations, some of which are more systematically recovered than others. The image engine disambiguates the meaning of an image by disambiguating its structure.
Image Grammars
A grammar is a combinatorial engine: a set of rules for combining representations and for determining what those combinations mean. Image grammars are engines for parsing and understanding images. They “identify, map out, and catalog high-density clusters” in image space, ideally in a way that reflects our systematic abilities to group and comprehend those images (Zhu & Wu, 2023, p. 9). The development of image grammars (sometimes “scene grammars”) has a long history in the study of vision science, computer vision, and AI (see Geman et al. 2002; Zhu & Mumford, 2006, Lake et al., 2016). They explain the sorts of things one expects a grammar to explain, using the sorts of elements one expects grammars to contain.
Below are several toy illustrations of how image grammars might assign latent structures to an image, including some of the elements and combinatorial rules that generate those structures. Some models try to explain how we (or machines) can grasp simple kinds of images and patterns, where others traffic in rich natural images. In some models there is a very close correspondence between syntactic types and semantic types: the units of the image are those that represent surfaces, objects, and so on in the depicted scene. In other models, there is more slippage between the syntax and the semantics (Clowes, 1971).
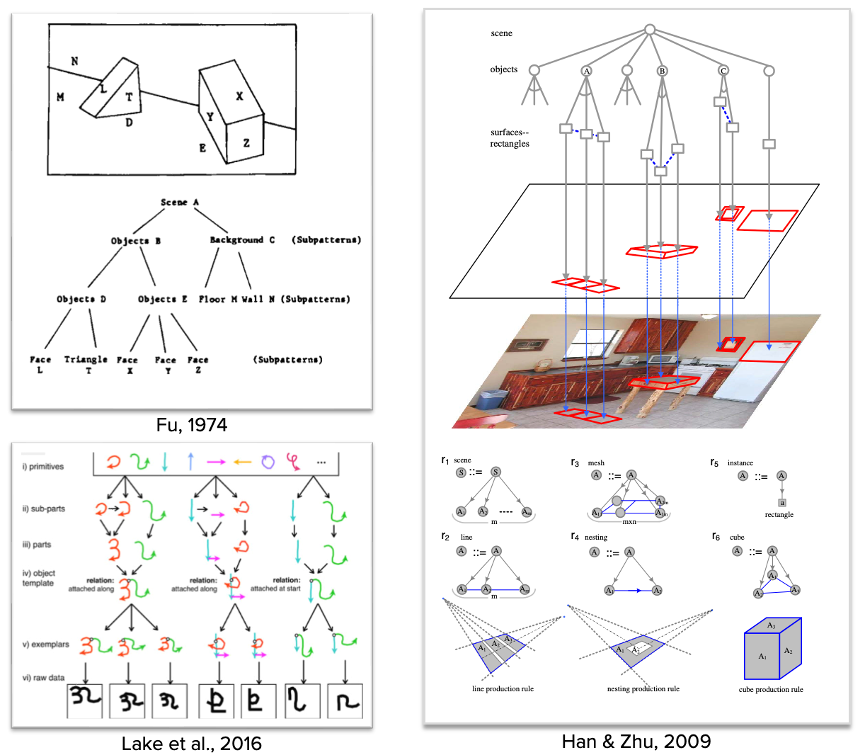
It is true that images do not look like they have a grammar. The tree-like structures that are illustrated as descending (or ascending) from the image hardly seem like they are parts of the image itself. But that’s true of sentences too. Sentences have a one-dimensional “outer form,” a string of letters or sounds that is perceived or produced, as well a hierarchical “inner” form that is mentally represented (Bever & Poeppel, 2010). The sentence’s inner form has a claim to being the true vehicle of linguistic representation, with the more salient outer form being the mere external “read-out” of the sentence (Chomsky, 2016). While our minds contain sub-systems that can extract this inner form automatically and effortlessly, that form is not available to casual observation or introspection. An explicit account of a sentence’s inner form must be inferred as an explanation of linguistic facts.
If images did have a grammatical structure, there’s no reason to expect that they would wear that structure on their sleeve either. The “outer form” of the image may be a flat array of colored points. The “inner form” might be a complex structure, inaccessible to casual inspection or introspection, but which our psychological systems systematically extract in the course of viewing and interpreting the image. Maybe it is the inner structure of the image that has a claim to being the true vehicle of pictorial representation, the true image, while the flat array of colored points is merely a peripheral externalization, or “print-out,” of that underlying representation. If we have an image engine, then the latent structure that it constructs for an image does not merely reduce or redescribe the image’s message; it explains it.
The Imagistic Mind
We do not just perceive images; we perceive with images. The visual system transforms the light at the eye into “intrinsic images” of objects and scenes (Hume, 1739; Kant, 1781/1998; Burge, 2022; Block, 2023; Barrow & Tenenbaum, 1978; Marr, 1982). In mental imagery, we generate internal images that may be arbitrarily divorced from our current circumstances, but which are integral for planning, reminiscing, and longing (Kosslyn, 2006). There is a wealth of evidence that these representations are also, as the psychologist Stephen Palmer wrote, “selectively organized data structures” (1977, p. 442). Vision composes rich, structured images of the objects around us in response to the traces that those objects leave on our eyes. There is a real possibility that when we view images out in the world, as when we view the world with images in the head, we are deploying an “image engine.”
Give me an image, and I will not be able to tell you in any serious way what its underlying structure is. That, as with language, is a matter of scientific discovery. It may be that we cannot ultimately give a scientifically adequate account of the grammar of images, whether these images reside in the world or in the head. But I think it is worth taking seriously the possibility that images have more structure and richness than is often allowed. More generally, though language may have a unique grammar, grammar is not unique to language. Analogical representations need not be considered “mere agglutinations” of information (see also Camp, 2007; Lande, 2023; Clarke, 2023).
This is not to say that images are just another species of language, but rather that we have many “infinite gifts” and that the combinatorial engines that power them can have many forms.
* * *
These ideas are explored at greater length in my paper, “Pictorial Syntax” (Lande, 2024).

Image: Damon Rarey, in Joseph Deken’s Computer Images: State of the Art (1983)
Notes
[1] If I isolate and trace the arms of the brass lamp, I can just barely get that the composition is a unified image. That’s all the more evidence for something like the rule of connecting lines.
References
Abell, C. (2009). Canny resemblance. Philosophical Review, 118(2), 183–223.
Abusch, D. (2020). Possible-worlds semantics for pictures. In D. Gutzmann, L. Matthewson, C. Meier, H. Rullmann, & T. Zimmermann (Eds.), The Wiley Blackwell companion to semantics (pp. 1–31). Wiley-Blackwell.
Barrow, H. and Tenenbaum, J. (1978). Recovering intrinsic scene characteristics from images. In Hanson, A. and Riseman, E. (Eds.), Computer Vision Systems, pp. 3–26. Academic Press.
Barthes, R. (1977). Rhetoric of the image. In Heath, S. (ed.), Image Music Text, pp. 32–51. Fontana Press.
Bermúdez, J.L. (2010). Two arguments for the language-dependence of thought. Grazer Philosophische Studien, 81: 37–54.
Bever, T.G. & Poeppel, D. Analysis by synthesis: A (re-)emerging program of research for language and vision. Biolinguistics, 4(2–3): 174–200.
Block, N. (2023). The border between seeing and thinking. Oxford University Press.
Burge, T. (2022). Perception: First form of mind. Oxford University Press
Camp, E. (2007). Thinking with maps. Philosophical Perspectives, 21(1): 145–182.
Chomsky, N. (2000). New horizons in the study of language and mind. Cambridge University Press.
Clarke, S. (2023). Compositionality and constituent structure in the analogue mind. Philosophical Perspectives, 37(1): 90–118.
Clowes, M. (1971). On seeing things. Artificial Intelligence, 2(1): 79–116.
Deke, J. (1983). Computer images: State of the art. Stewart, Tabori & Chang Publishers, Inc.
Fan, J. E., Hawkins, R. D., Wu, M., and Goodman, N. D. (2019). Pragmatic inference and visual abstraction enable contextual flexibility during visual communication. Computational Brain & Behavior, 3(1): 86–101.
Fu, K. S. (1974). Syntactic methods in pattern recognition. Academic Press
Geman, S., Potter, D. F., and Chi, Z. (2002). Composition systems. Quarterly of Applied Mathematics, 60(4): 707–736
Gombrich, E. (1960). Art and illusion: A study of the psychology of pictorial representation. Phaidon.
Goodman, N. (1968). Languages of art: An approach to a theory of symbols. The Bobbs-Merril Company, Inc.
Greenberg, G. (2021). Semantics of pictorial space. Review of Philosophy and Psychology, 12(4): 847–887.
Han, F. and Zhu, S.-C. (2009). Bottom-up/top-down image parsing with attribute grammar. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(1): 59–74.
Haugeland, J. (1981). Analog and analog. Philosophical Topics, 12(1): 213–225.
Hopkins, R. (2023). Design and syntax in pictures. Mind & Language.
Hume, D. (1739/2009). A treatise of human nature. (P.H. Nidditch, Ed.). Clarendon Press.
Kant, I. (1787/1998). Critique of pure reason (P. Guyer & A. Wood, eds.). Cambridge University Press.
Kosslyn, S. M., Thompson, W. L., and Ganis, G. (2006). The case for mental imagery. Oxford University Press.
Kulvicki, J. (2020). Modeling the meanings of pictures. Oxford University Press.
Lake, B. M., Ullman, T. D., Tenenbaum, J. B., and Gershman, S. J. (2016). Building machines that learn and think like people. Behavioral and Brain Sciences, 40.
Lande, K. (2023). Contours of vision: Towards a compositional semantics of perception. The British Journal for the Philosophy of Science.
Lande, K. J. (2024). Pictorial syntax. Mind & Language.
Leborg, C. (2006). Visual grammar: A design handbook. Princeton Architectural Press.
Marr, D. (1982). Vision: A Computational investigation into the human representation and processing of visual information. The MIT Press.
Palmer, S. E. (1977). Hierarchical structure in perceptual representation. Cognitive Psychology, 9(4):441–474.
Perdreau, F. and Cavanagh, P. (2011). Do artists see their retinas? Frontiers in Human Neuroscience, 5(171).
Schier, F. (1986). Deeper into pictures: An essay on pictorial representation. Cambridge University Press.
Sober, E. (1976). Mental representations. Synthese, 33(2–4): 101–148.
Ullman, T. D., Spelke, E., Battaglia, P., and Tenenbaum, J. B. (2017). Mind games: Game engines as an architecture for intuitive physics. Trends in Cognitive Sciences, 21(9): 649–665.
Willats, J. (1997). Art and representation: New principles in the analysis of pictures. Princeton University Press.
Yang, C. (2006). The infinite gift: How children learn and unlearn the languages of the world. Scribner.
Zhu, S. C. and Mumford, D. (2006). A stochastic grammar of images. Foundations and Trends in Computer Graphics and Vision, 2(4): 259–362.
Zhu, S.-C. and Wu, Y. N. (2023). Computer vision: Statistical models for Marr’s paradigm. Springer